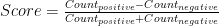[This was the top post of the week on the Reddit community dataisbeautiful, where it garnered 1.6 million impressions ]
The US federal government ran a deficit of $1.8 trillion (6.4% of GDP) in 2024. This is expected to increase to 6.7% of GDP in 2025.
Some notable developments in the federal government’s expenditure:
Interest payments have grown to a hefty $890b per year, more than three times what they were a decade ago
Tariff revenue more than doubled to $16b in April 2025, but this barely makes a dent in the overall deficit
Most of the outlays are in social spending (i.e. welfare), military expenditure, and interest payments for previously incurred debt
Breaking down the expenditures explains why it is so difficult to “cut the deficit”: interest servicing and spending on the military and social security are structural costs. It is not a straightforward matter to reduce these outlays. Where the focus tends to be – DOGE touts cuts in areas like weather forecasting and food safety– are generally much smaller areas of expenditure.
*I am calculating net social spend as revenue from employment taxes and unemployment insurance [minus] outlays for income and social security.
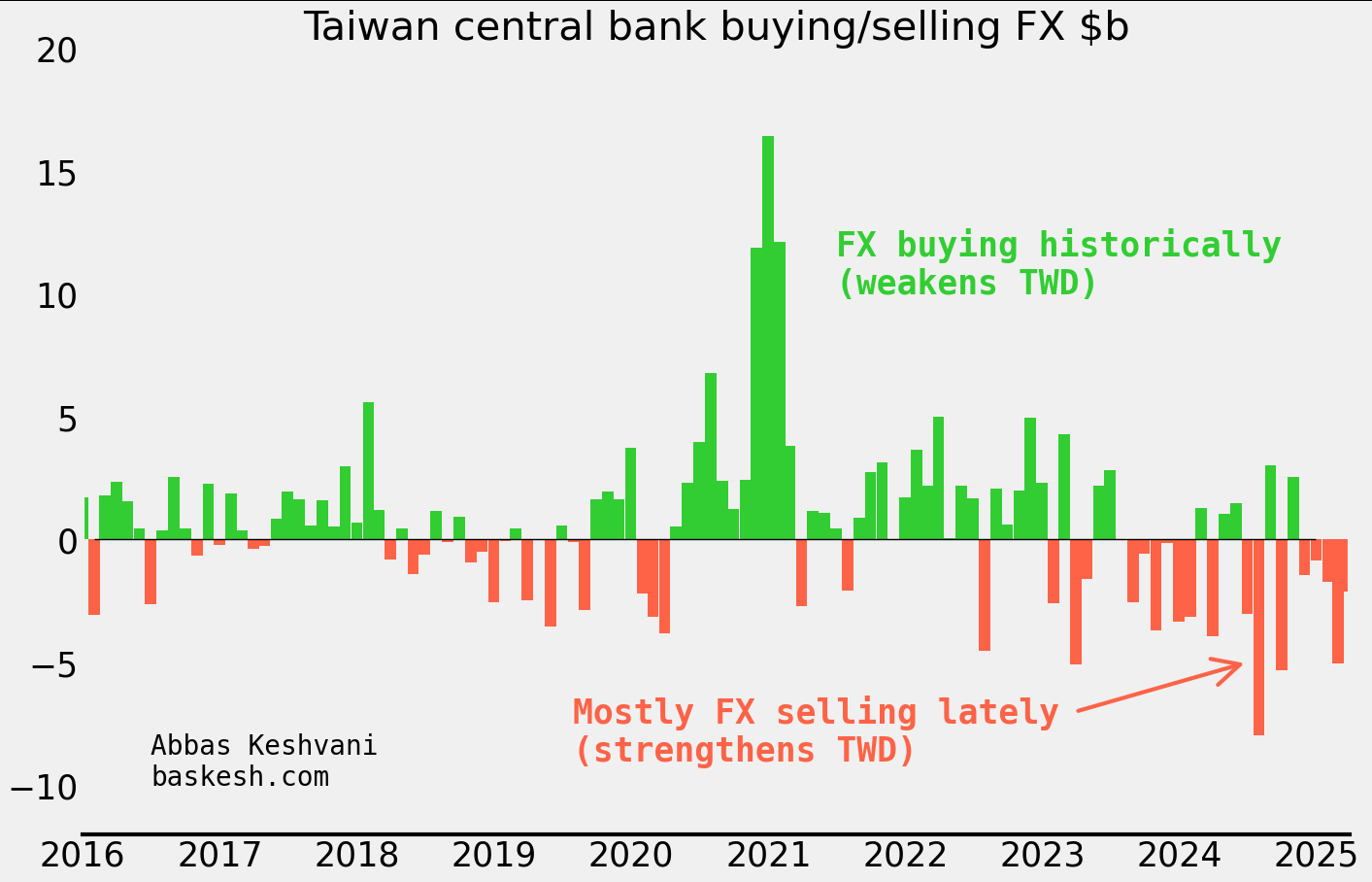
The Taiwanese dollar (TWD) soared as much as 8% this month. This would be a colossal move for any currency, but especially for TWD, which usually moves less than 0.5% daily. Folks have been scrambling to figure out who was responsible for this spectacular rally, from exporters to life insurance companies to the central bank.
It’s the balance of payments, stupid. I type this on a laptop made in Taiwan, contributing to the island’s current account surplus of 14% of its GDP. Such a bounty would ordinarily lead to appreciation of TWD, but much of it is recycled back out by life insurance companies (“lifers”) and the central bank buying foreign assets like US Treasuries. What’s more, exporters tend to retain a lot of their proceeds in foreign currency. Altogether, the trifecta of lifers, exporters, and the central bank have been building up an epic long-dollar position for years.
Central bank started selling dollars. The trifecta holding a floor under USD/TWD began to unravel in 2024. In the first half of the year, the central bank sold $9.1 billion of FX reserves — its biggest sale yet. I estimate that since then, they have picked up the pace of selling even further to an average $2 billion per month into March this year.
My own estimate of the central bank intervention amounts
There were clues… Around the time that the central bank began selling dollars, TWD started trading stronger than my framework1 implied (this is all before the big move recently). This outperformance of TWD indicated that the currency was experiencing a regime shift. There is a lesson here: when one’s framework starts to “break down” it is a sign that something is afoot. This discrepancy from the model foreshadowed the 15 sigma move that we saw in early May 2025.
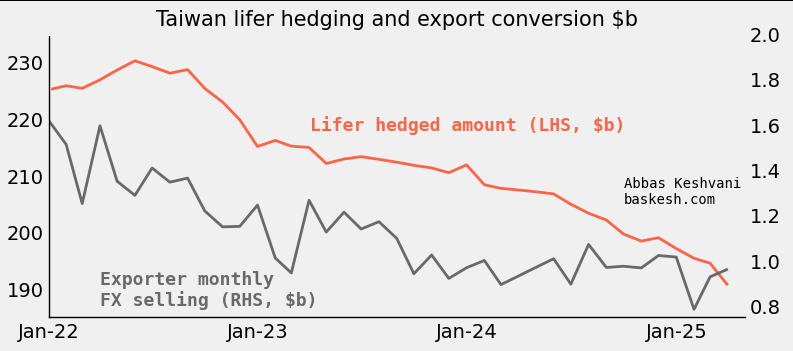
Lifers and exporters were not the first movers… To be clear, over the period that the central bank was selling dollars, insurers were actually reducing USD/TWD hedges (i.e. selling less dollars) and exporter conversion of FX proceeds had fallen to its lowest ever rate (i.e. selling less dollars). So the CBC was the first mover in the trifecta that had been keeping TWD weak until now.
… but they must have piled in. Lifers and exporters had too large a long-dollar position to not take notice of the change at the central bank. Lifers own almost $700 billion in foreign assets, and 60% of this is FX-unhedged. Exporters were holding on to their own mega-pile of dollars. Based on TWD’s historical sensitivity to flows, I estimate that the big move in early May 2025 was enabled by a conversion of around $45 billion going through. There are few parties who can manage such a colossal flow, but lifers and exporters fit the bill.
American scrutiny. So there you have it: the trifecta propping up USD/TWD started unraveling last year when the central bank began selling dollars, leading exporters and lifers to panic-sell dollars this month. But why did the central bank start this? One possible explanation is that they are keen to avoid the ire of the United States, where the Treasury department keep Taiwan on a “monitoring list” of economies whose currency practices merit scrutiny — being on the list is especially hazardous during a trade war. I would have expected the US to give Taiwan a pass, given the latter’s strategic importance, but this is not the first time that Taiwan has reduced FX intervention due to American scrutiny.
Plenty of downside for USD/TWD. Lifers could still sell another $400 billion — around ten times the amount that I estimate went through recently. If expectations for TWD cannot be anchored again, there is plenty of downside for USD/TWD. Until the central bank receives the green light from the US Treasury to buy FX, USD/TWD will be left to the preferences of lifers and exporters. This means that when the dollar is selling off, it will be prone to violent swings.
1In my framework for TWD, I model the currency against historical patterns by key actors including lifers, exporters, and the central bank.
Bonds issued by the US government, known as US Treasuries, sit at the center of the world’s financial constellation. What happens to Treasuries ripples through to every other market: bonds of other countries, stocks, FX, and crypto. Sure the FX market is larger, but the dollar takes its cues from US Treasury yields.
My raison debt. Given the importance of the key 10-year yield, I have modeled it as a function of macroeconomic and financial data (i.e. inflation, issuance at auctions, rainfall in Ohio, etc…). The result is a reliable fair value estimate of the 10y yield, but also a framework to evaluate the importance of new data: yes, the jobs numbers came in weak, but what does that mean for the 10y yield in basis points?
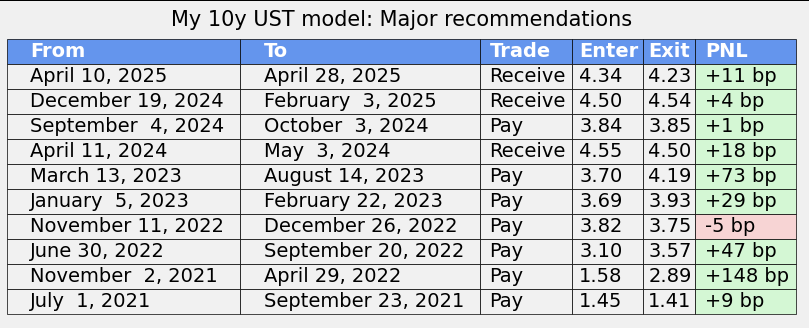
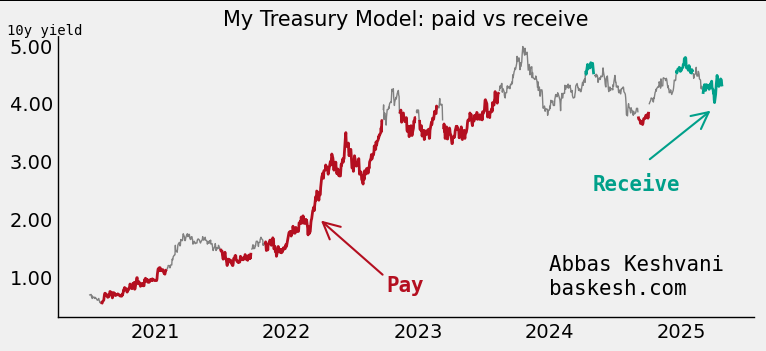
It works. A measure of the model’s success is that it has produced 10 major recommendations in the last four years, and 9 of them have worked, producing over 500 basis points in returns.
The model produced prescient paid recommendations in 2022 (high inflation) and 2023 (SVB), and received recommendations in 2025 (expectations for Fed cuts; still live).
These are just the major recommendations. Each row denotes a period when the model was generally paid or received, but within each period the model may have tactically turned neutral for a short period (i.e. model was neutral for one day during the April 2024 received trade)
How does it work? At the core of the model is a fair value estimate for the 10y yield, itself a blend of key macroeconomic and financial data. Independent variables are smoothed, regressed, and weighted. In addition to that, I apply a valuation filter that dictates the actual execution of the model.
An honest backtest. The above model was trained on 2017-2021 data. I then backtested it out-of-sample from 2021 onwards, and this has produced the >500bp in returns.
Current model recommendation: Receive 10y (yearend forecast of 3.50%). The model lives here.
Trump’s tariffs have captivated the current news cycle and bear major ramifications for the cost of goods, global supply chains, and America’s influence in the world. The goal of his policy is to narrow America’s trade deficit, which he calls a “national emergency”.
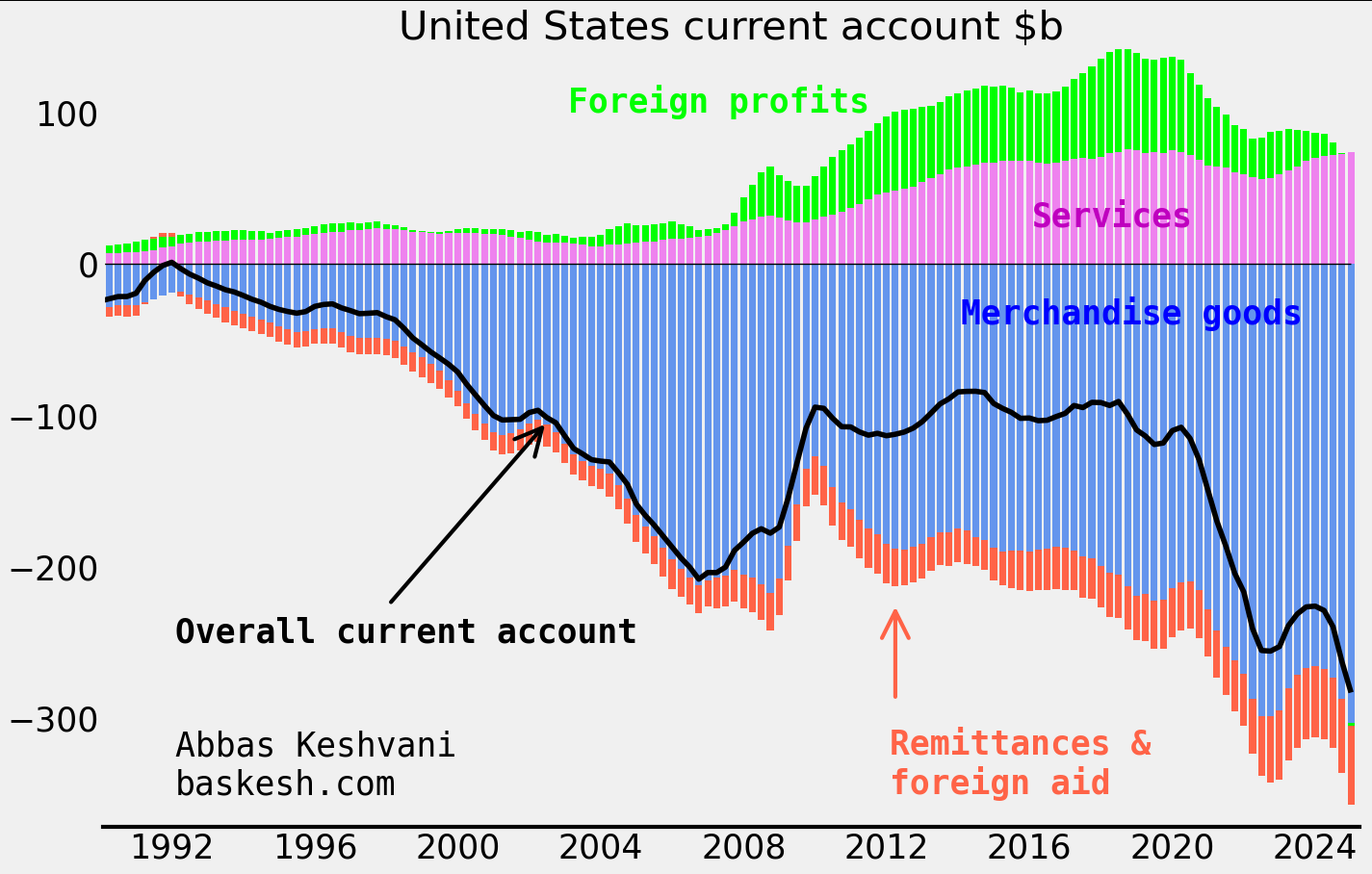
A gaping goods deficit. America experienced its first modern goods deficit in 1971, a product of the postwar industrial revival in Europe and Japan. Since then, US demand for foreign merchandise like cars and electronics have ballooned the deficit to $1.2 trillion or 3.7% of GDP in 2024. The goods deficit (blue in the below chart) dwarfs America’s surplus from services, like management consulting and software licenses. Aside from goods, other sources of outflows like foreign aid are also being targeted by Trump scaling back on America’s defense commitments.
Quarterly data; smoothed four quarters
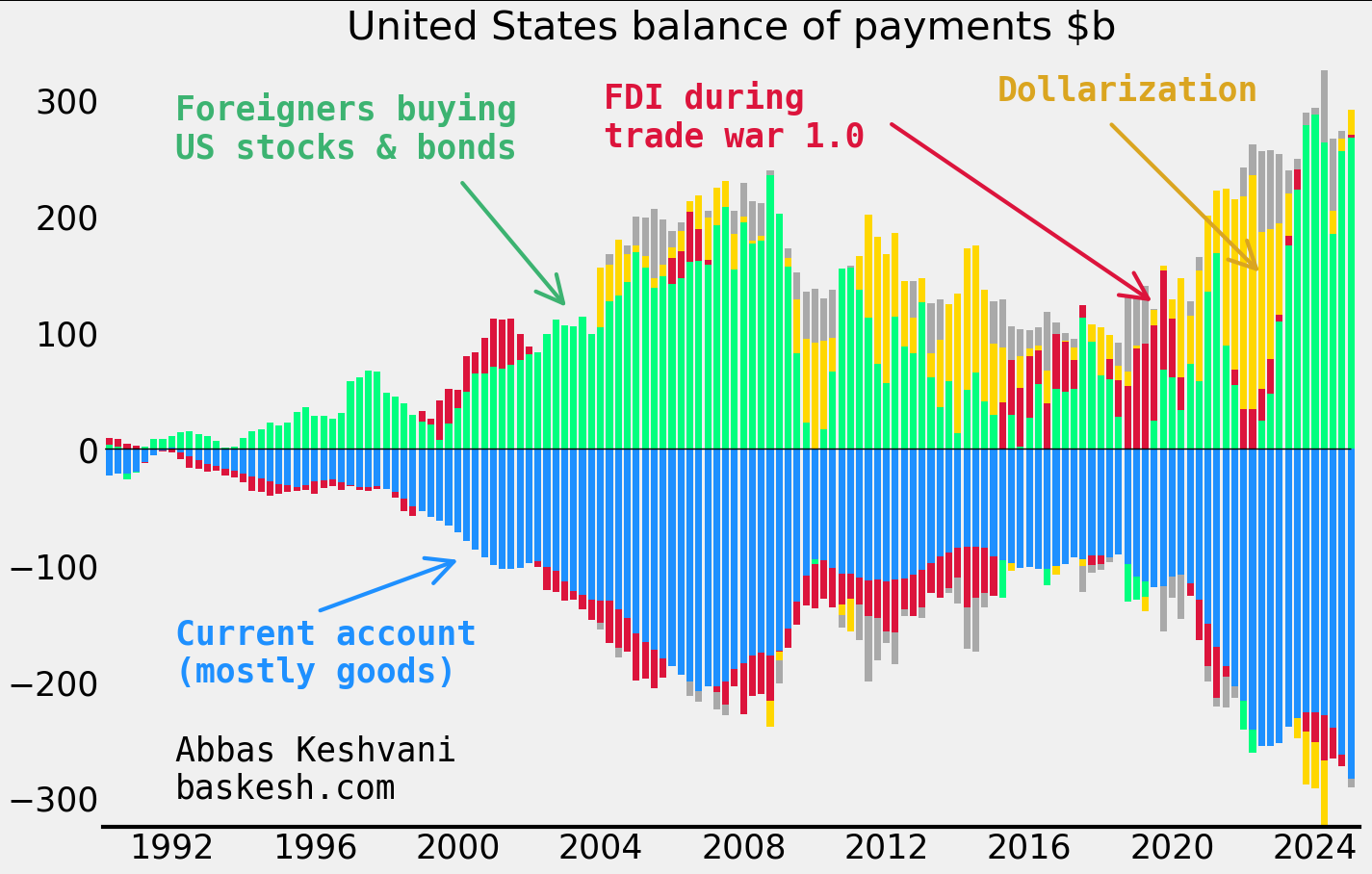
The money does come back eventually… The outflows from America’s goods deficit generally return back to the country via inbound foreign portfolio investment. As a result, the Chinese own 2.8% of outstanding US Treasuries, Koreans own 1.5% of Tesla stock, and so on… We can see this in America’s balance of payments (BOP), which tracks all cross-border flows, visualized in the next chart. US BOP essentially comprises of a wide current account deficit (blue) and large foreign inflows into American stocks and bonds (green).
… But not everyone likes this deal. The administration does not consider America’s BOP dynamic — a current account deficit funded by financial inflows — to be a healthy state of affairs. Robert Lighthizer, the architect of the trade war in the first Trump presidency, describes it as a transfer of wealth to foreigners: “aggressors now own both those assets and the future income of a large segment of the U.S. economy”.
Quarterly data; smoothed four quarters; dollarization includes inflows into US dollar deposit accounts.
What about industrial policy? There are other ways to tackle the good deficit. Tariffs seek to hamper imports. Meanwhile, “industrial policy” or government support of strategic sectors can be used to support exports. But industrial policy, which requires a strong centralized government like China’s, is tricky under America’s fractious political system.
What about a weaker dollar? Another option is to try to weaken the dollar, which would simultaneously support exports and stymie imports. But currency devaluation would carry major geopolitical ramifications for Washington. In any case, whether it is intentional or not, Trump is already pursuing a weaker dollar policy by demanding the Fed cut rates.
Around the same time that the United States experienced its first modern goods deficit in 1971, Nixon upended the international monetary order. He halted the international convertibility of dollars for gold and engineered a devaluation of his currency against those of Germany and Japan. Today’s goods deficit is significantly larger, both in nominal terms and as a share of GDP. It will probably remain a key focus for the White House.
Every month has a different market flavor, from Chinese growth to easing of Federal Reserve policy. To illustrate this, I conducted natural language processing on daily market commentary. The result is a recap, for the last two years, of the various themes that the market has focused on.
Since 2023, we have seen the market fret about Chinese growth (summer 2023); over-anticipate Fed easing before paring back expectations (winter 23/24); focus on Japan as the Bank of Japan finally started hiking (spring 2024); analyze actual Fed easing (fall 2024); salivate on potential Chinese easing (winter 2024); and stress about tariffs (year-to-date).
We are now in the fourth month of tariffs being the main macro focus, and April thus far has seen a spike in the word “negotiation”.
Acknowledgements: The research I am analyzing is by BNZ, who leverage their timezone vantage point — as the first to see the trading day open — by producing a thorough recap of the previous day.
Method: I used my own Python code to load the reports, extract text from them, omit generic words like “the” and “lower”, count the most common words for every month, and use a mix of rules to determine every month’s macro meme. The code did all of this — over 500 reports to parse — in 178 seconds. You can contact me if you would like to see my code.
In my last post I forecasted a Trump victory based on him retaining key swing states like Florida, Ohio, Pennsylvania, and Wisconsin (although not Michigan).
But reports of a surge in absentee/mail-in voting signups by Democrats in some of these states raise questions about whether Trump will really be able to hold on to them.
Basics
Mail-in voting is the same as absentee voting. Different states use different terms, but both refer to the same thing: voting using the postal service.
Universal mail-in voting is a sub-category of absentee/mail-in voting, where the state will send every voter a ballot in the mail, whether or not they request one. The voter then has a choice to vote by mail, vote in person, or not vote at all.
Colorado, Hawaii, Oregon, Utah, Washington, California, Nevada, Vermont, and New Jersey have universal mail-in voting. None of these are swing states.
Trump has criticized universal mail-in voting: “Absentee ballots, by the way, are fine… But the universal mail-ins that are just sent all over the place, where people can grab them and grab stacks of them, and sign them and do whatever you want, that’s the thing we’re against.”
Crunching the numbers
Let’s take a look at the absentee/mail-in data for Florida, Pennsylvania, Wisconsin, and North Carolina, where I noted that the outcome was relatively uncertain.
One of the headline-grabbing figures it that around 650,000 more Democrats have signed up for absentee ballots than Republicans have, indicating that there will be a surge in turnout among Biden voters in November.
But it is important to consider the possible sampling bias at play here:
A Monmouth survey (6-Aug to 10-Aug) reported that 72% of Democrats but only 22% of Republicans were likely to vote by mail
A Pew survey (27-Jul to 2-Aug) showed 58% of Biden supporters would prefer to vote by mail, but only 17% of Trump supporters felt the same way
A TargetSmart survey (21-May to 27-May) showed that 52% of Democrats and 33% of Republicans intended to vote by mail
One of the main reasons for this divide could be that Trump’s rhetoric against mail-in voting has turned usage of the facility into a partisan issue. The bottom line is that using absentee signups to estimate voter turnout could be overestimating the Democrat edge.
Given that Democrats tend to favor absentee voting, for a state like Florida where Democrats and Republicans are roughly matched in numbers, we should expect there to be more Democrats signing up for absentee ballots in that state. In fact I estimate that, ceteris paribus, Democrats should have an edge in absentee ballot signups by around 819,000.
I use numbers of people that voted for either party in 2016 and the respective propensity for voters for each party to sign up for an absentee ballot (conservative 52-33 propensities) to estimate the below expected edges for the Dems:
Numbers for FL and NC are from state governments; using estimates by polling firm TargetSmart for PA and WI
As you can see, although Democrat absentee signups are impressive, for each state they are less than what they should be given the propensity of Democrats to vote by mail anyway. This would indicate that enthusiasm among Democratic voters is weak, a fact I pointed to in my analysis of polling and primary data.
Putting it altogether…
Data for FL and NC from state governments; data for PA and WI from pollster TargetSmart
Florida: Polls are razor-thin, while primary and absentee data suggests lackluster engagement among Democrats.
North Carolina: polling and primary data is very close, while absentee signups for the Democrats are disappointing.
Pennsylvania and Wisconsin: polls show Biden with a decent lead, but less people voted in those states’ Democrat primaries this year than in 2016. In line with my conservative approach, I am giving these states to Trump.
Since my call remains a Trump win with just 289 electoral college votes (306 in 2016), the loss of just Florida to Biden, or any two smaller states from the above table would change the outcome of the election. So I will keep monitoring polling and absentee data (the above table has been updated for polling data) and revise my calls if required.
Timelines: It takes longer to count a mail ballot than a regular one because officials must open thick envelopes, inspect the ballots, and confirm voters’ identities. The large number of people opting for absentee voting may delay the timeline for knowing the outcome of the election. Also, given that Democrats are more likely to use absentee ballots, the initial results we get on polling day are likely to skew the initial outcome in favor of Trump. All of this means we could be in for an “election week” rather than election day, with controversy to follow if the final results differ from those on election day.
If you have questions or feedback, feel free to reach out to me: abbas [dot] keshvani [at] gmail.com.
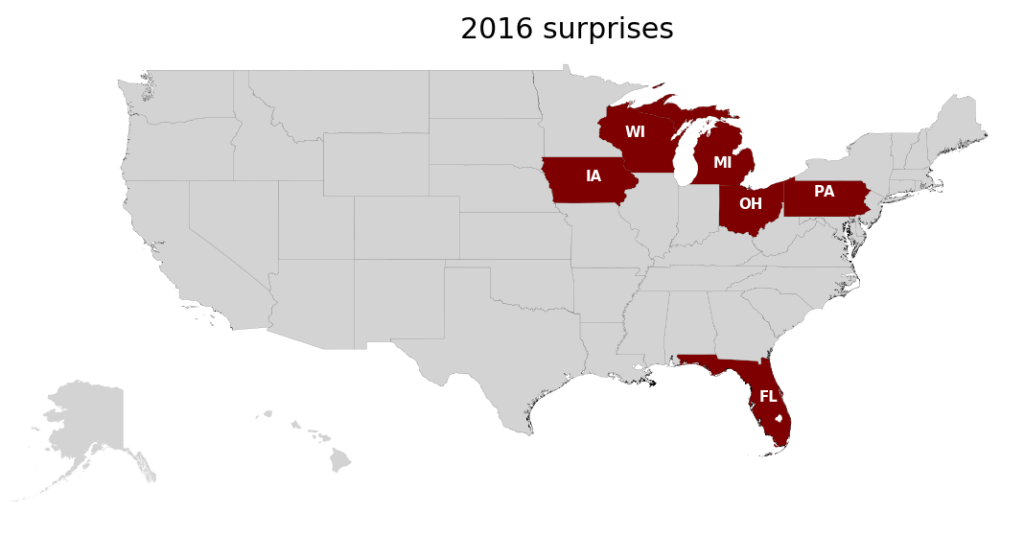
In the summer of 2016 I built a model that combined past election, polling, and primary data to accurately predict that Donald Trump would be elected the US president later that year. My model showed the GOP taking 300 electoral college votes (they ended up getting 306) and correctly predicted surprise outcomes in Florida, Iowa, Ohio, Michigan, and Wisconsin.
Surprise victories in FL, IA, PA, MI, OH, WI catapulted Trump into the White House
Primer on the system: The US presidential election comprises 51 separate elections – one per state. Each state is worth a certain number of electoral college votes (e.g. California has 55, Wyoming has 3). If a candidate wins a state by plurality, then they bag all the electoral college votes of that state (except Maine and Nebraska which allocate their votes by some degree of proportional representation). The winner of the election is the person to get 270 electoral college votes in total.
Not all states matter as much: California almost always votes Democrat and Alabama almost always votes Republican. But states like Florida and Ohio tend to swing around between the two parties, which is why they are called “swing states”. This means that the variation in results for different elections comes down to whom the people in swing states vote for. For example, Trump won in 2016 because of shock victories in the swing states of Florida, Iowa, Pennsylvania, Michigan, Ohio, Wisconsin.
Watch out for the swing states in white – they can vote either way
Methodology overview: As in previous years, the winner of the election will be decided by swing states like Florida, Pennsylvania, Michigan. If you find a way to reasonably forecast how these states will vote, then you have a decent election model. To do this, I will use primary and polling data.
Primaries: Using this data is a little more challenging this year because we don’t have “good quality” primary data. Although the GOP technically held primaries this year, using turnout at those primaries as a proxy for voter enthusiasm for the party is problematic, since Trump is running again anyway. So instead I am comparing 2020 Democrat primary turnout with 2016 Republican primary turnout adjusted for estimated changes in population in those 4 years.
Polls: After the twin shocks of Brexit and Trump in 2016, many people are rightly skeptical about relying on polling alone. In reality, in all the states where Trump won by surprise, Clinton was leading in the polls by only 3-4%. Many of these opinion polls sampled a few hundred participants, which means that the margin of error would have been around 4% or even more. I did not use polls in 2016 if they were not conclusive and I am doing the same this year.
Conservative approach: I am opting for a conservative approach, which means that in the event of a close call like Florida – thin margins on primary, polling, and election numbers – I assume that the state will remain with Trump this year. In Pennsylvania and Wisconsin, although the polling favors Biden, the Democrat primaries did not garner enough turnout in the primaries to assure me that enough people will turn out for Biden in November.
What’s the bottom line? With the polling information we currently have, I expect Trump to hold on to the White House with 289 electoral college votes (270 needed).
I predict Trump will keep all of his 2016 swings except Michigan
Georgia, Texas, Arizona have voted for the Republican candidate with comfortable margins in recent elections, so I am giving them to Trump. Iowa tends to swing around but Trump won that state by 10% in 2016 so I am giving it to him.
Florida and Ohio polls are too close for me to attach much significance to them right now. I would rather trust primary data, which shows similar levels of enthusiasm for the Democrats as in 2016 (FL) or reduced enthusiasm (OH). They also go to Trump.
Pennsylvania and Wisconsinpolls show Biden with a decent lead, but less people voted in those states’ Democrat primaries this year than in 2016. I am giving them to Trump.
Michigan primaries indicated a surge in enthusiasm for Democrats and this is backed by the polls. The state only marginally supported Trump in 2016, so I am giving it to Biden.
North Carolina is too close to call. Trump won it by less than 4% in 2016 and the poll and primary data is very close. For now I am keeping it with Trump in line with my conservative approach, but even if Biden wins it, it alone would not change the outcome.
Breakdown of key state calls
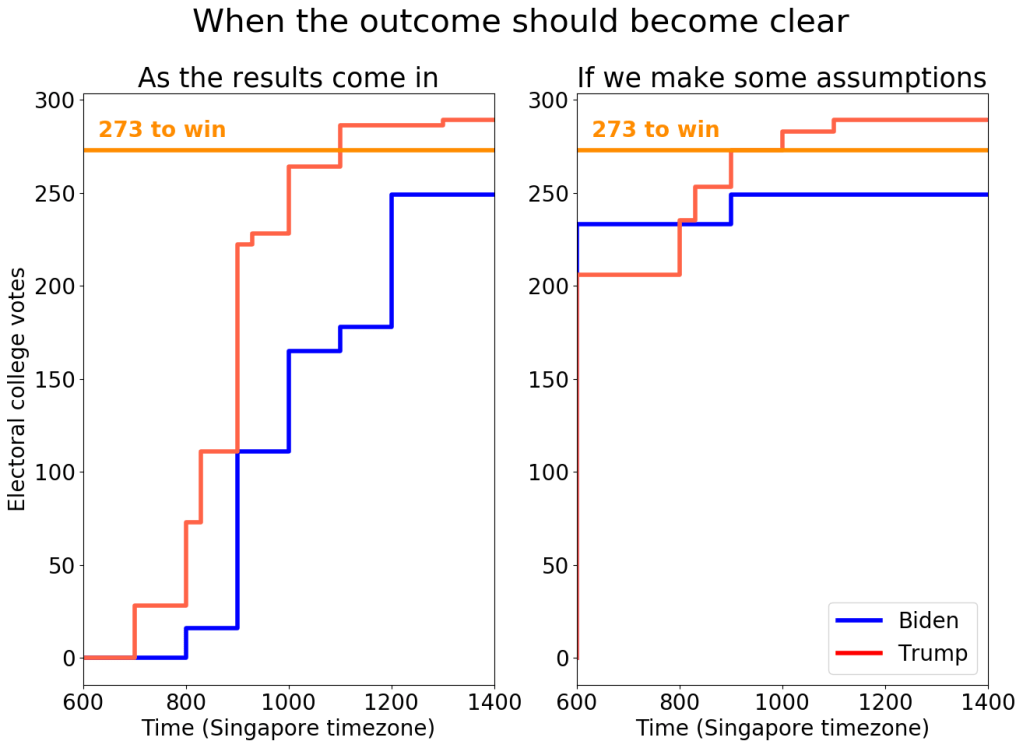
Timeline of the results: Different states declare the winner at different times, with east coast states like New York typically reporting before west coast states like Washington state. This means that we can also predict when the outcome will become apparent.
If a state reported results at the moment polls closed, then a Trump victory would be confirmed at 11am SGT on 4-Nov (3am London, 4-Nov / 10pm New York, 3-Nov). In reality, you would have to wait around an hour for the results to start trickling in. We can go one step further and make assumption about how the safer states will vote. This way, we should know the outcome even earlier from around 10am Singapore (4 Nov) / 2am London (4 Nov) / 9pm New York (3 Nov).
Results should be clear by 10am Singapore (4-Nov) / 2am London (4-Nov) / 9pm New York (3-Nov)
Risk factor: postal vote. The data that we have so far shows that more mail ballots have been requested by Democrats than Republicans in Florida, Pennsylvania, and North Carolina. In Wisconsin the parties are matched, and in Michigan it appears the GOP has an advantage. On first glance this sounds positive for Biden, but it is not clear whether mail ballots represent the participation of new voters who previously did not vote, or merely existing voters changing the way they vote. It is worth noting that there may exist a sampling bias in counting mail-ballots because Trump’s campaign against mail voting might have turned usage of the facility into a partisan issue.
Is a tie possible? Yes. If both candidates get 268 electoral college votes, then it is considered a tie. Two things can happen:
Members of the electoral college can “go rogue” (i.e. back a candidate who did not win the plurality in that state), breaking the tie. They can do this even in the absence of a tie.
Alternatively, the new House will elect the President when they meet on 6 January 2021. Each state delegation gets one vote (i.e. 50 votes). Since the GOP control 26 state delegations, the Republicans will end up winning the White House in this scenario.
Regardless of how (if) a tie is eventually resolved, this would be a controversial result. The last time such a tie took place was in the 1800s.
Maine and Nebraska: Unlike the other states, Maine and Nebraska allocate electoral college votes based on some degree of proportional representation. I am assuming that Maine will give one electoral college vote to the GOP this year (ME-2) while the rest go to the Democrats, as was the case in 2016. Similarly, I assume Nebraska will give one EC vote to the Democrats (NE-2) and the rest to the GOP.
If you have questions or feedback, feel free to reach out to me: abbas [dot] keshvani [at] gmail.com. All charts created on Python.
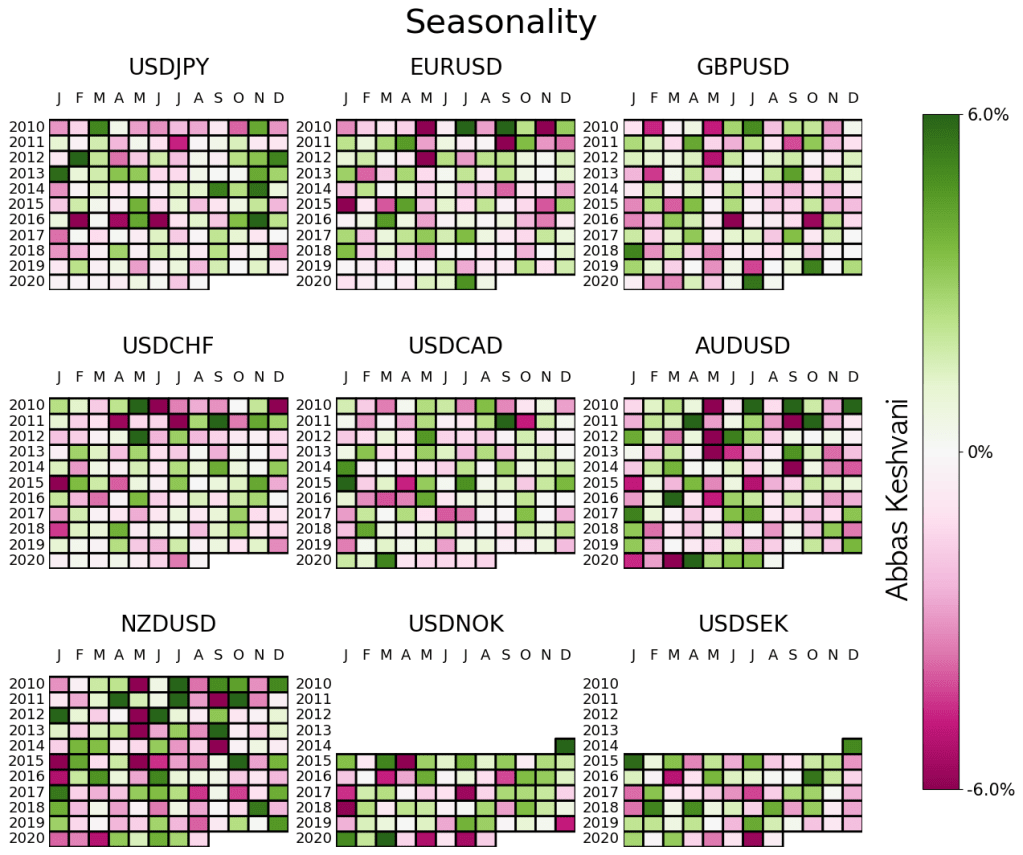
Currency traders pay a lot of attention to seasonality. “NZDUSD tends to sell-off in August” is often cited as an argument (combined with other considerations, of course) to either short the pair or at least not go long.
Yes, NZDUSD tends to sell-off in August, but does that mean you should do it?
Come September, we will probably move on to the seasonality tendencies for that month, and there is seldom a review of whether seasonality “worked” in August.
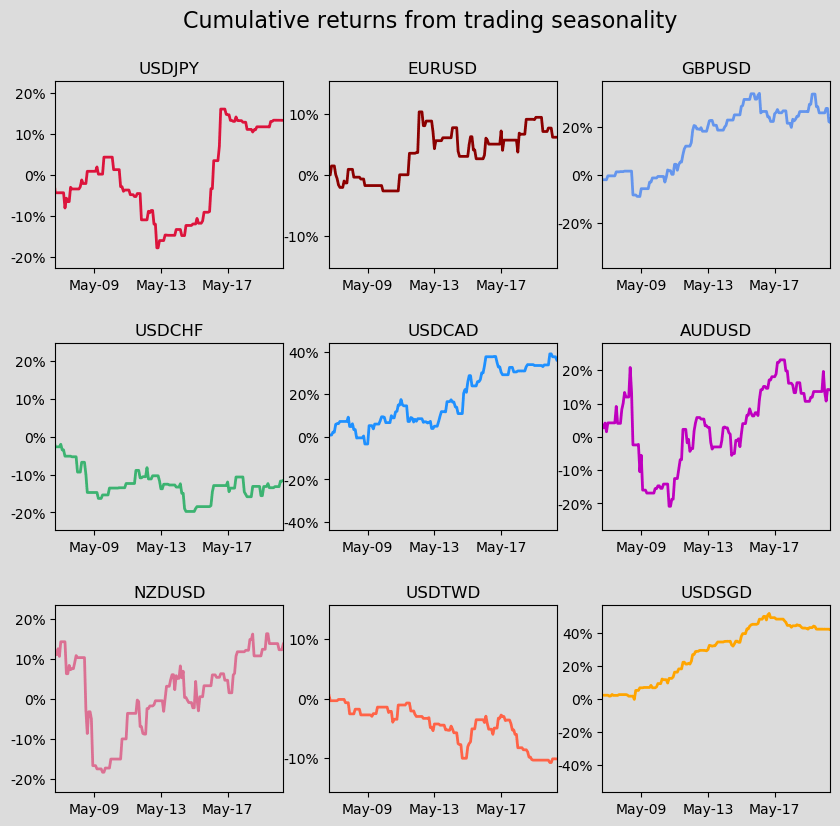
So here I’m doing just that. I am “trading” every seasonality recommendation to test whether there is any value in this metric at all. If a currency pair exhibits strong seasonality for a month – i.e. it strengthened or weakened in 4 out of 5 months in previous years – then I long/short that pair.
Its earlier stuff was better
The results are decent, but they’re neither unanimous (some currencies do better than others) nor consistent over time (lately, seasonality hasn’t been doing that well).
Seasonality has never been a particularly successful strategy for USDCHF or USDTWD
For currencies where it has been successful, that success petered out around 2017
Combined returns of a seasonality strategy for G10 excluding NOK and SEK
So the short answer is that this is a strategy whose best years are probably behind it. Since 2017, you wouldn’t have lost much on seasonality, but you would not have made much either.
At the August meeting of the RBI, the Indian central bank kept the repo rate, its benchmark interest rate, unchanged. Around half of economists had expected a policy rate cut (India is in a pandemic after all!). But inflation in the country has exceeded the upper-bound of the RBI’s target range, and a lot of economists correctly forecasted that the central bank would not cut.
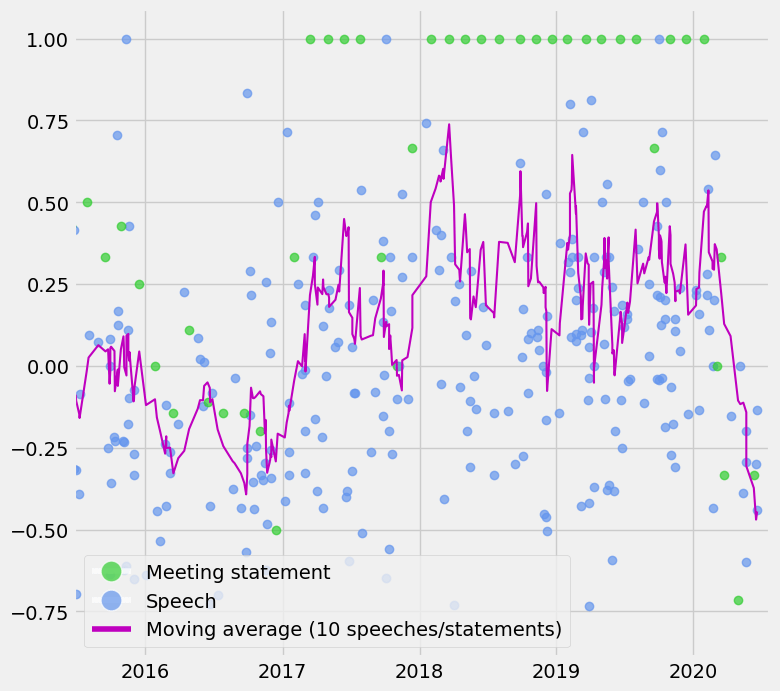
Between speeches, statements, and economic data, there is a lot to track for the RBI. So I have produced an RBI sentiment index in an attempt to objectively quantify and automate the tracking of:
Monetary policy statements (around 4-6 per year)
Speeches (over 20 last year)
CPI prints (12 per year)
Interpretation: The index is a moving average of the last 10 statements/speeches/CPI prints and can oscillate between -1 and +1. A score of +1 means that the RBI sounds optimistic about the economy and inflation is high, so one can reasonably expect the policy rate to be increased. -1 means the RBI sounds pessimistic and that inflation is low, so we can expect rate cuts.
As you can see the index has come off quite a bit since March, mostly due to pessimistic rhetoric as Covid-19 has taken a toll on India’s economy. The index would have fallen further if not for high inflation prints recently. But that is the point: the index should reflect the constraints imposed by inflation (i.e. you can be pessimistic about the economy but unable to cut due to high inflation).
An interesting overlay is between this index and bond yields. Low bond yields indicate that the market expect the central bank to cut rates, but as you can see, the RBI might be thinking differently right now. Even if you look past high inflation, some of the recent speeches and the August meeting statement show an improvement in RBI sentiment.
Details of the index:
NLP to automate scoring of rhetoric:I have used Python to automate the process of scraping all speeches and scoring them on a scale of -1 (pessimistic about the economy) to +1 (optimistic). While I was at it, I also did the same process for all RBI statements. The methodology is explained in more detail here.
Adding inflation data to the mix: I was worried that RBI speeches and statements were not adequately discussing inflationary pressure. This is particularly problematic for a country like India, which dealt with double digit inflation as recently as 2013 and where the CPI index has swung from 2.1% in January 2019 to 6.9% in July 2020. Compare that to the US, where core PCE inflation has mostly observed a humble range of 1-2%.
There are so many “words” around Python. There is clearly an entire ecosystem here. Here I break it down un-comprehensively.
Python is the language. You run Python on one of the following:
Terminal / command prompt: This is the black screen with white/green text used by computer geniuses in movies. Very basic, you can’t click anything.
Text editor: Not as “bare” as Terminal – has basic functionality. Examples include Atom, Vim, Notepad (yes you can run Python on the thing you use to jot down reminders). Technically Jupyter is not a text editor – it’s a web application – but it behaves like a text editor.
Integrated Development Environment (IDE): comes with bells and whistles, which make working on Python easier. Using an IDE is like using Word instead of Notepad to write an essay. Examples include Spyder, PyCharm, IDLE.
Anaconda is a bundle which includes Python as well as Spyder (IDE) and a button which opens up Jupyter on your web browser. I use Anaconda to use Spyder to use Python, if that makes sense.
Which one is the best one to use? It depends on what you want and I have not tested them all, but I like Spyder for data science and analysis.
Members of the Federal Open Market Committee, the body which decides the Fed’s interest rate policy, have their words closely scrutinized for hints about what the next policy change could be. Aside from the official policy-setting meetings (around eight per year), FOMC members give speeches throughout the year (78 in 2019).
Here I use natural-language processing (NLP) to assign a score to each of those speeches, as well as official FOMC statements.
As expected, the index shows that recent Fed speeches have been relatively negative in their tone.
Method:
The formula I use to calculate a speech’s score is based off the number of positive words and negative words in that speech/statement.
A score of +1 means that a speech had only positive words like “efficient”, “strong” and “resilient”, while -1 means it had only negative words like “repercussions”, “stagnate”, and “worsening”. The dictionary I use to determine whether a word is positive is based off (I have modified it) a 2017 paper published by the Federal Reserve Board1.
One also has to account for negation. A statement like “growth is not strong” has a positive word in it (“strong”) which should actually be counted as a negative word. As such, if a positive word is within three words of a negation word like “not” or “never”, then it is treated as a negative word. On the other hand, a negative word near a negation word (“growth is not poor”) is simply not counted, rather than treated as a positive word.
I downloaded the speeches and statements, did the NLP analysis, and produced the charts on Python.
Relation with yields:
Here I chart the Fed sentiment index against the US 2y yields, as well as the sentiment scores of the official meeting statements. The index moved higher from late 2016 to early 2018 as the Fed started hiking policy.
However in early 2018 the sentiment index indicated that the Fed had turned less positive, but yields continued moving higher as the hiking cycle continued. It is also important to note that sometimes a shift in FOMC thinking/language drives market price-action, and sometimes it is the other way round, so one cannot expect the index to always presage higher or lower yields.
As we go into the September FOMC meeting, where some people are expecting the Fed to announce yield curve control, keeping an objective eye on Fed sentiment will become even more important.
1Correa, Ricardo, Keshav Garud, Juan M. Londono, and Nathan Mislang (2017) – Sentiment in Central Banks’ Financial Stability Reports. International Finance Discussion Papers 1203.
Following my recent post about the most referenced topic in FX commentary (in my case, excellent daily commentary from BNZ), I received a number of questions from readers about whether topic X was being talked about more or less.
So I visualized the data differently for all those interested – this time as time series. Each chart show the number of references made to a particular topic on a monthly basis.
References to the trade war, Fed and Trump increased in May. Meanwhile references to Covid-19 have been consistently sliding lower every month since March.
See last post for methodology. Everything done on Python.
An updated version of this chart for June 2020 was shared with subscribers of TLR Wire, the esteemed economics newsletter managed by Philippa Dunne and Doug Henwood.
The financial sector produces a lot of commentary on the things affecting markets. A lot of this year’s commentary has been focused on Covid-19, but before that there was a lot of literature being produced on the US-China trade war and Brexit.
Here I chart, for every month, the most talked about issue in financial literature. I did this by pulling out hundreds of daily FX commentary pieces from BNZ (who do a solid job on recapping the previous day’s events) and analyzing the most used words (excluding the generic ones like “the” and “markets” and “economy”).
Naturally the total number of references to Covid-19 for a given month is not just the number of times “Covid-19” is printed, but also “coronavirus” and “virus”. A similar methodology is adopted for the US-China trade war.
While Covid-19 remained in the top 5 of topics for May, we can see the focus is starting to balance out, with the the Fed getting the most number of references as we approach the June meeting (which will have the Fed’s quarterly economic projections (which they skipped in March). There was also a pick-up in references to “Trump” and “trade” this month, suggesting that we aren’t quite done with the US-China theme.
Data mining, text-analysis and chart all done on Python.
The Federal Reserve (or “Fed”) is the central bank of the United States, in charge of setting interest rates, regulating banks, maintaining the stability of the financial system, and providing financial services such as swap lines (which temporarily provide foreign central banks with dollars).
The Fed has its own balance sheet, which means its owns assets such as US government bonds (“Treasuries”) and has liabilities such as reserves (cash which financial institutions keep with the Fed) and currency (which technically counts as a liability because the Fed “owes” you things for the dollars you hold – historically it was gold, but now it is other assets such as bonds).
In the aftermath of the Great Recession from 2008, the Fed undertook Quantitative Easing (QE), which means it created new money to buy bonds and loans. This increased its balance sheet from roughly $1 trillion in 2008 to $4.5 trillion in 2014.
From 2014 to 2018, the Fed stopped buying additional bonds and loans under QE, and its balance sheet stabilized.
From 2018 to 2019, the Fed started to sell some of its assets, but this only reduced the balance sheet to around $3.8 trillion.
Around the Covid-19 outbreak, the Fed started buying assets again and also temporarily provided dollars to other central banks. This has ballooned the Fed’s balance sheet to around $6.6 trillion today.
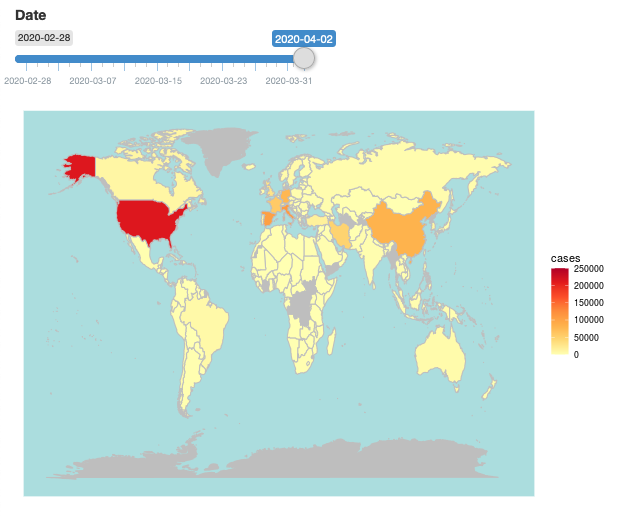
R lets you create charts and graphs in image form. But the Shiny package lets you create those same charts and graphs in interactive format. I created my first Shiny chart: a world map of confirmed Covid-19 cases. Check it out here.
Unfortunately I cannot embed the app into this website right now, so the below is merely a screenshot. Click the link to play with the app itself.
Data from a variety of public sources, compiled by the John Hopkins Center for Systems Science and Engineering.
This is a practical tutorial on performing PCA on R. If you would like to understand how PCA works, please see my plain English explainer here.
Reminder: Principal Component Analysis (PCA) is a method used to reduce the number of variables in a dataset.
We are using R’s USArrests dataset, a dataset from 1973 showing, for each US state, the:
rate per 100,000 residents of murder
rate per 100,000 residents of rape
rate per 100,000 residents of assault
% of the population that is urban
Now, we will simplify the data into two-variables data. This does not mean that we are eliminating two variables and keeping two; it means that we are replacing the four variables with two brand new ones called “principal components”.
This time we will use R’s princomp function to perform PCA.
Preamble: you will need the stats package.
Step 1: Standardize the data. You may skip this step if you would rather use princomp’s inbuilt standardization tool*.
Step 2: Run pca=princomp(USArrests, cor=TRUE) if your data needs standardizing / princomp(USArrests) if your data is already standardized.
Step 3: Now that R has computed 4 new variables (“principal components”), you can choose the two (or one, or three) principal components with the highest variances.
You can run summary(pca) to do this. The output will look like this:
As you can see, principal components 1 and 2 have the highest standard deviation / variance, so we should use them.
Step 4: Finally, to obtain the actual principal component coordinates (“scores”) for each state, run pca$scores:
Step 5: To produce the biplot, a visualization of the principal components against the original variables, run biplot(pca):
The closeness of the Murder, Assault, Rape arrows indicates that these three types of crime are, intuitively, correlated. There is also some correlation between urbanization and incidence of rape; the urbanization-murder correlation is weaker.
*princomp will turn your data into z-scores (i.e. subtract the mean, then divide by the standard deviation). But in doing so, one is not just standardizing the data, but also rescaling it. I do not see the need to rescale, so I choose to manually translate the data onto a standard range of [0,1] using the equation:
In my last post, I talked about how America had depressed oil prices by increasing its supply. Recall this graph which shows that the supply glut is primarily caused by increased American supply (the top pink line is America):
The glut is mostly due to America producing more oil
Since low prices are mainly caused by American oversupply, a decrease in American supply will have a major impact on prices. And it does look like American supply might wind down. The next graph shows how American oil production responds (eventually) to the number of oil rigs in America.
Just to clarify, “rigs” here refers to rotary rigs – the machines that drill for new oil wells. The actual extraction is done by wells, not rigs. But American oil supply shows a remarkable (lagged) covariance with rig count. From the 1990 to 2000, the number of rigs decreased, and oil supply followed it down. Then, when the number of rigs jumped in 2007, oil supply also rose with it.
Note that the number of American rigs has plummeted since the start of 2015. It is no coincidence that oil prices hit a record low in January 2015. At these paltry prices, oil companies have less of an impetus to dig for more oil.
The number of oil rings in America has halved since January 2015
The break-even price for shale oil varies according to the basin (reservoir) it comes from. A barrel from Bakken-Parshall-Sanish (proven reserves: 1 billion barrels) costs $60, while a barrel from Utica-Condensate (4.5 billion barrels) costs $95. The reserve-weighted average price is $76.50. These figures were calculated by Wood McKenzie, an oil consulting firm, and can be viewed in detail here.
As the number of rigs has halved to 800, the United States will not be able to keep up its record supply. Keep in mind that wells are running dry all the time, so less rigging will eventually mean less oil. Perhaps finally, the glut is about to end, with consequences for oil prices. To put things in perspective, the last time America had only 800 rigs (end January 2011), oil was at $97 a barrel.
Oil probably will not return to $100 a barrel. If it does, shale oil will become profitable again (the threshold is $76), American rigs will come online again, supply will increase and prices will come down again. So oil will have to find a new equilibrium price to be stable. A reasonable level to expect for this equilibrium is around $70, the break-even price for shale.
There will probably be a lag in the reduction of American supply: Note how oil supply does not immediately respond to the number of rigs. But things move faster when expectations are at play. On the 6th of April, traders realized Iranian rigs were not going to come online as fast as they thought. Oil prices rose 5% in one night. American supply does not have to come down for prices to drop: traders simply have to realize prices will come down.
Data from US Energy Information Agency and Baker Hughes, an oil rig services provider. Graphs plotted on R.
This article was republished by the Significance, the official magazine of the American Statistical Association and Royal Statistical Society (UK).
You have probably heard that the price of crude oil has tumbled from $115 per barrel (159 litres, an archaic but established unit of measurement) in June 2014 to $54 in March 2015.
The price of oil has halved in 9 months.
Why oil has plunged so far: The drop has been caused by a supply glut (oversupply), as the below graph shows. The top line in pink is America, not Saudi Arabia:
The glut is mostly due to America producing more oil.
Although most of us think of Saudi Arabia as the world’s largest oil supplier, in actual fact the United States has had this title since 2013. In 2014, America was responsible for around half of the net increase in world oil output, due to a boom in the shale gas industry there. Its increase was akin to adding one Kazakhstan to the world! All of this excludes all the natural gas the US got out of fracking, which also makes it the #1 gas supplier.
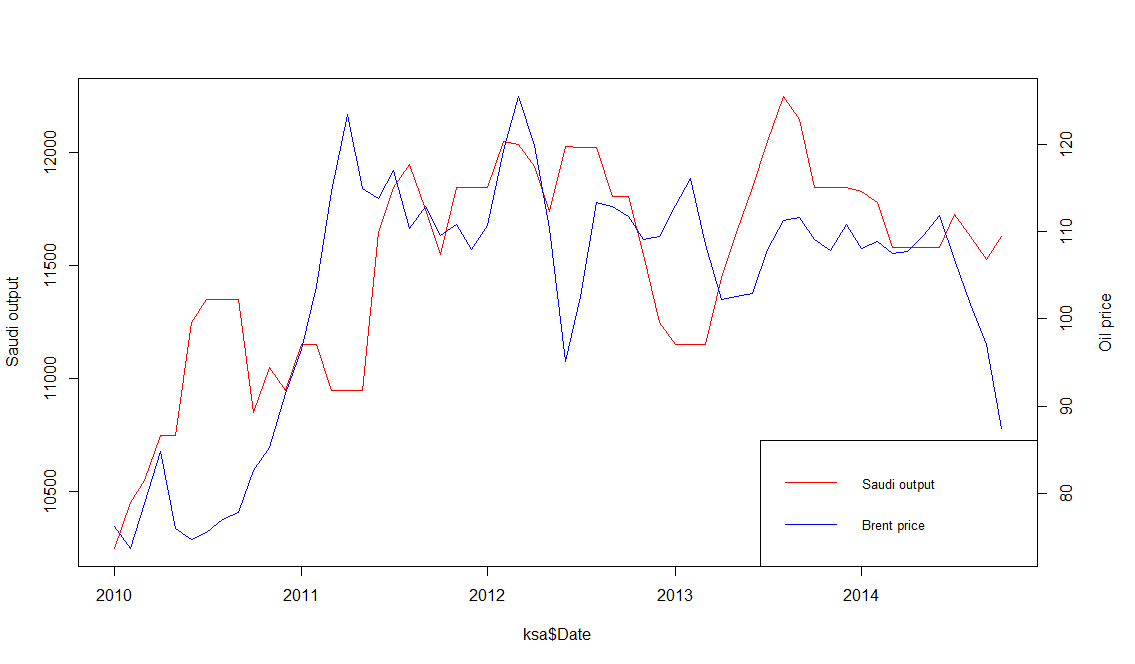
Historically, Saudi Arabia has played a stabilizing role in world oil prices, by adjusting its output to ensure global supply is stable. The below graph show how Saudi output increased to lower prices when they were high, and vice versa. However, since July, the Saudis have not responded to newly low oil prices by decreasing output. In fact, the Kingdom have insisted that they would rather bear lower oil prices than decrease their market share (read: be squeezed out by shale).
The Saudis have historically stabilized prices, but no more.
Saudi Arabia is backed by the other members of the Gulf Cooperation Council – UAE, Qatar and Kuwait. Together, the GCC are responsible for more than a fifth of world oil output, so their inaction towards falling prices has been instrumental in ensuring that oil prices remain low. But why have the Saudis and their allies been so passive?
Motive 1 – Shale: One reason the Kingdom is depressing prices is to thwart the growth of the nascent shale gas and bitumen oil industries in America and Canada. The threat from these new industries to Saudi Arabia is real – In October, America ceased Nigerian oil imports, even though Nigeria exported almost as much oil to America as Saudi Arabia as recently at 2010. Meanwhile, Canada steadily increased its exports of bitumen oil to America during the same period.
However, new shale projects require $65 oil to break even. At $53 a barrel, the shale boom has been paused, and several investments have been called off, their returns in doubt (although many existing wells remain online). If the Saudis allow prices to increase, the threat of shale will likely resume, so it does not look like they will allow prices to return to their pre-June levels. But the current price level is sufficiently low to keep the threat at bay, so the Saudis need not increase output further. At the same time, $53 oil will stop new shale projects from coming offline, so it is unlikely that North America can contribute to the supply glut any further, either. It is for these reasons that oil proces are unlikely to tumble much further.
Motive 2 – Iran: However, I believe the Saudis have also depressed prices to hurt Iran and Russia, both of whom make most of their export revenue from oil. Iran’s expanding influence in the Middle East has rattled the Saudis considerably. In addition, both Iran and Russia remain staunch defenders of the Syrian government, which the Saudis and Qataris despise. The Saudi’s reserves of $900bln provide the kingdom with a buffer, but will likely force Iran and Russia to think twice about expensive foreign projects like Syria, right?
But it does not look like low oil prices have reduced Iranian, or even Russian, involvement in Iraq and Syria. Iranian General Soleimani is openly marching through Iraq as an “advisor”, while Iran-backed militia have made the bulk of gains against IS. Meanwhile Assad has held onto power, two years after most media outlets pronounced him as good as overthrown. All of this has happened against the backdrop of low oil prices. Thus, it does not look like there is much value in continuing the Saudi strategy of depressing oil prices to curb Iranian influence.
Other producers, like Nigeria: The second graph shows that other oil producers like Nigeria (produces 2.3m barrels a day or 2.6% of world oil: more than Qatar but less than UAE) have generally kept output constant. Most major oil producers – nations like Nigeria, Venezuela and Iraq – cannot afford to decrease oil sales, which are critical to their economies. They are probably not too happy about low oil prices, but have little choice in the matter. Finally, fortunately or unfortunately, the conflict in Libya has not depressed their oil output.
Wild card Iran: Iran exported 3m barrels of oil per day in 2006, and sanctions have reduced this number to a meager 1.2m per day. A barrage of nuclear-related sanctions since 2006 have imposed an embargo on Iranian oil exports to the EU, prohibited investments in Iran’s oil industry, and barred banks from mediating transactions involving Iranian oil. But as sanctions are eased, Iran’s oil exports will certainly increase, and this may lower prices even further.
However, the timelines for increased Iranian oil exports are unclear. They depend on the speed at which sanctions are repealed and the pace at which Iran can ramp-up output: The timelines for repealing nuclear-related sanctions imposed by the P5+1 will only be unveiled on 30thJune 2015; Iran has 30m barrels of oil ready to ship out immediately, but beyond this stockpile, it will takes years for Iran to bring its oil industry up to speed.
If sanctions are eased and Iran increases oil exports within a year, Saudi Arabia may actually reduce their output. Allowing prices to drop further will not serve the kingdom’s interests. Current prices are already low enough to keep shale at bay. The kingdom could very well lower prices to hurt Iran, but low oil prices do not seem to have worked to curb Iranian influence so far.
Any Iran-related decreases in oil prices will also be bound by the $50 psychological resistance (although this was breached in January) and the 2008 low of $34.
In summary, I do not think will see $100 oil any time soon, but I also do not think oil prices will drop much further than they already have.
Data from US Energy Information Administration; graphs produced on R.
Read this to understand how PCA works. To skip to the steps, Ctrl+F “step 1”. To perform PCA on R, click here.
What is PCA?
Principal Component Analysis, or PCA, is a statistical method used to reduce the number of variables in a dataset. It does so by lumping highly correlated variables together. Naturally, this comes at the expense of accuracy. However, if you have 50 variables and realize that 40 of them are highly correlated, you will gladly trade a little accuracy for simplicity.
How does PCA work?
Say you have a dataset of two variables, and want to simplify it. You will probably not see a pressing need to reduce such an already succinct dataset, but let us use this example for the sake of simplicity.
The two variables are:
Dow Jones Industrial Average, or DJIA, a stock market index that constitutes 30 of America’s biggest companies, such as Hewlett Packard and Boeing.
S&P 500 index, a similar aggregate of 500 stocks of large American-listed companies. It contains many of the companies that the DJIA comprises.
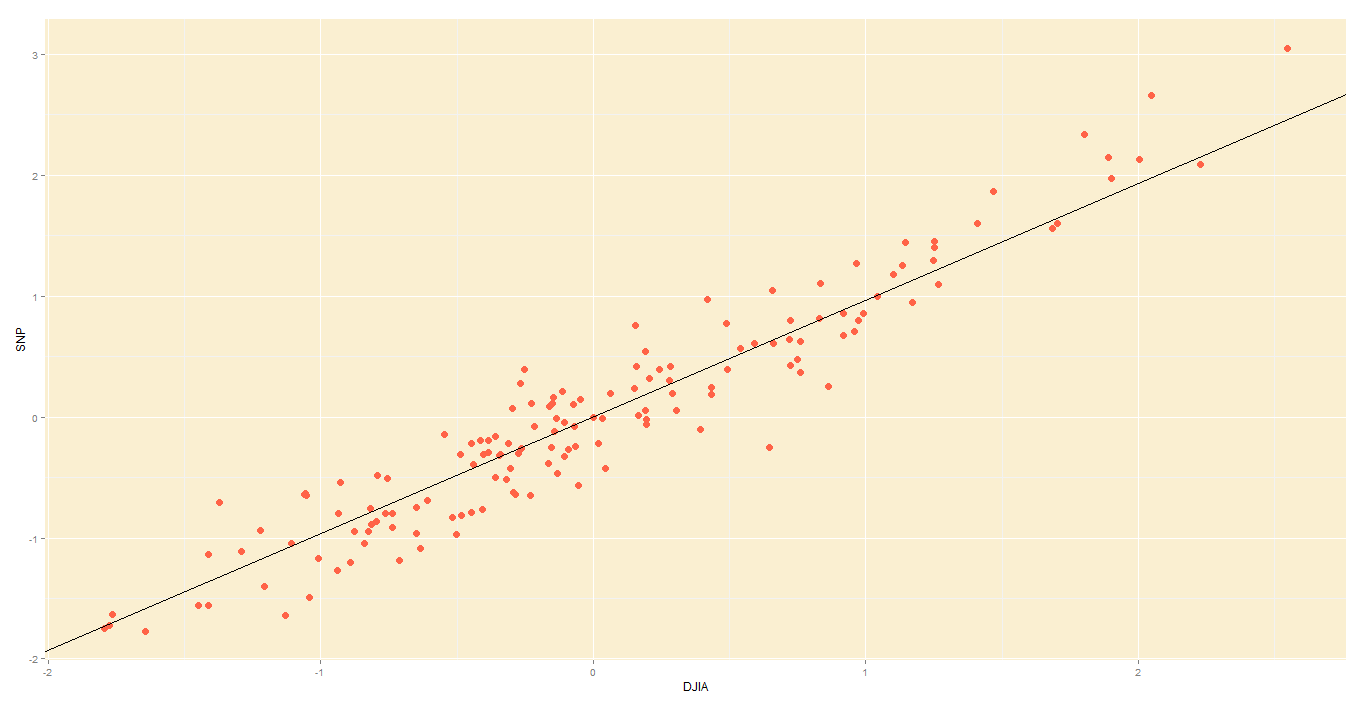
Not surprisingly, the DJIA and FTSE are highly correlated. Just look at how their daily readings move together. To be precise, the below is a plot of their daily % changes.
DJIA vs S&P
The above points are represented in 2 axes: X and Y. In theory, PCA will allow us to represent the data along one axis. This axis will be called the principal component, and is represented by the black line.
DJIA vs S&P with principal component line
Note 1: In reality, you will not use PCA to transform two-dimensional data into one-dimension. Rather, you will simplify data of higher dimensions into lower dimensions.
Note 2: Reducing the data to a single dimension/axis will reduce accuracy somewhat. This is because the data is not neatly hugging the axis. Rather, it varies about the axis. But this is the trade-off we are making with PCA, and perhaps we were never concerned about needle-point accuracy. The above linear model would do a fine job of predicting the movement of a stock and making you a decent profit, so you wouldn’t complain too much.
How do I do a PCA?
In this illustrative example, I will use PCA to transform 2D data into 2D data in five steps.
Step 1 – Standardize:
Standardize the scale of the data. I have already done this, by transforming the data into daily % change. Now, both DJIA and S&P data occur on a 0-100 scale.
Step 2 – Calculate covariance:
Find the covariance matrix for the data. As a reminder, the covariance between DJIA and S&P – Cov(DJIA, S&P) or equivalently, Cov(DJIA, S&P) – is a measure of how the two variables move together.
By the way,
The covariance matrix for my data will look like:
Step 3 – Deduce eigens:
Do you remember we graphically identified the principal component for our data?
DJIA vs S&P with principal component line
The main principal component, depicted by the black line, will become our new X-axis. Naturally, a line perpendicular to the black line will be our new Y axis, the other principal component. The below lines are perpendicular; don’t let the aspect ratio fool you.
If we used the black lines as our x and y axes, our data would look simpler
Thus, we are going to rotate our data to fit these new axes. But what will the coordinates of the rotated data be?
To convert the data into the new axes, we will multiply the original DJIA, S&P data by eigenvectors, which indicate the direction of the new axes (principal components).
But first, we need to deduce the eigenvectors (there are two – one per axis). Each eigenvector will correspond to an eigenvalue, whose magnitude indicates how much of the data’s variability is explained by its eigenvector.
As per the definition of eigenvalue and eigenvector:
We know the covariance matrix from step 2. Solving the above equation by some clever math will yield the below eigenvalues (e) and eigenvectors (E):
Step 4 – Re-orient data:
Since the eigenvectors indicates the direction of the principal components (new axes), we will multiply the original data by the eigenvectors to re-orient our data onto the new axes. This re-oriented data is called a score.
Step 5 – Plot re-oriented data:
We can now plot the rotated data, or scores.
Original data, re-oriented to fit new axes
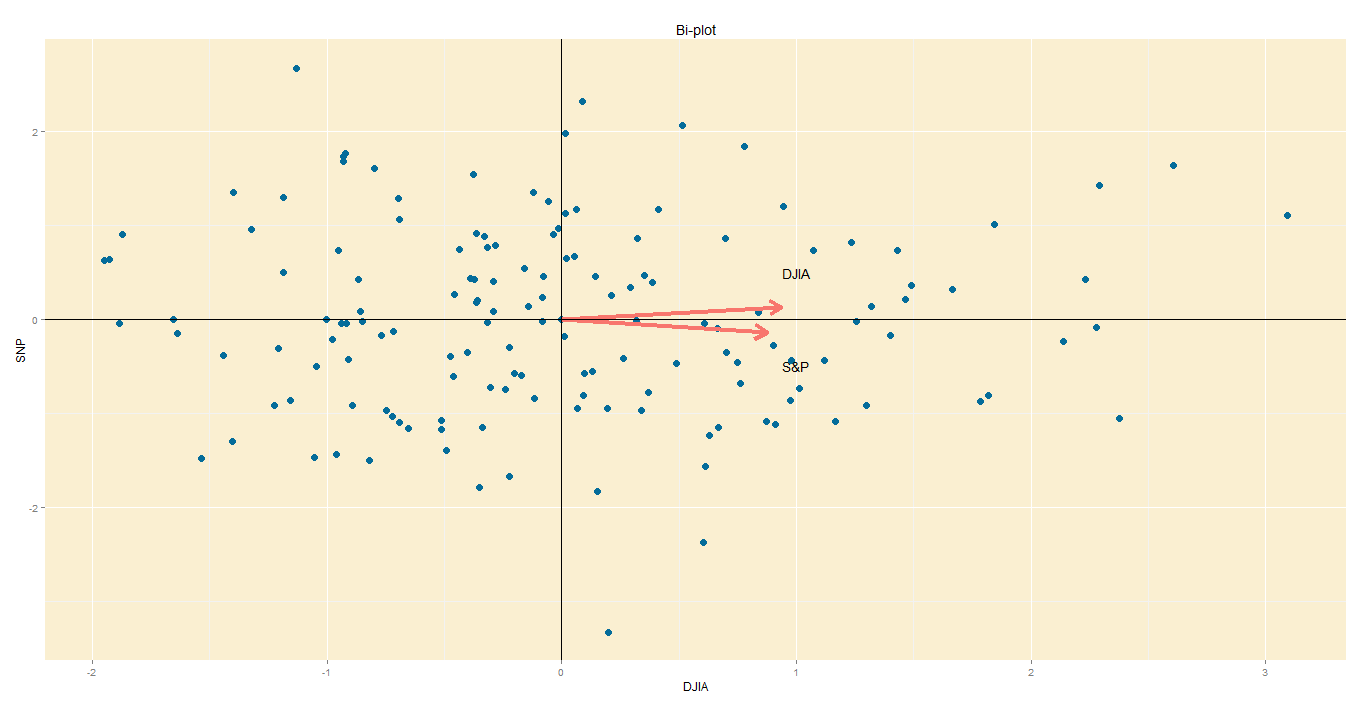
Step 6 – Bi-plot:
A PCA would not be complete without a bi-plot. This is basically the plot above, except the axes are standardized on the same scale, and arrows are added to depict the original variables, lest we forget.
Axes: In this bi-plot, the X and Y axes are the principal components.
Points: These are the DJIA and S&P points, re-oriented to the new axes.
Arrows: The arrows point in the direction of increasing values for each original variable. For example, points in the top right quadrant will have higher DJIA readings than points in the bottom left quadrant. The closeness of the arrows means that the two variables are highly correlated.
Bi-plot
Data from St Louis Federal Reserve; PCA performed on R, with help of ggplot2 package for graphs.