
The Akaike Information Critera (AIC) is a widely used measure of a statistical model. It basically quantifies 1) the goodness of fit, and 2) the simplicity/parsimony, of the model into a single statistic.
When comparing two models, the one with the lower AIC is generally “better”. Now, let us apply this powerful tool in comparing various ARIMA models, often used to model time series.
The dataset we will use is the Dow Jones Industrial Average (DJIA), a stock market index that constitutes 30 of America’s biggest companies, such as Hewlett Packard and Boeing. First, let us perform a time plot of the DJIA data. This massive dataframe comprises almost 32000 records, going back to the index’s founding in 1896. There was an actual lag of 3 seconds between me calling the function and R spitting out the below graph!


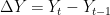
The first difference is thus, the difference between an entry and entry preceding it. The timeseries and AIC of the First Difference are shown below. They indicate a stationary time series.
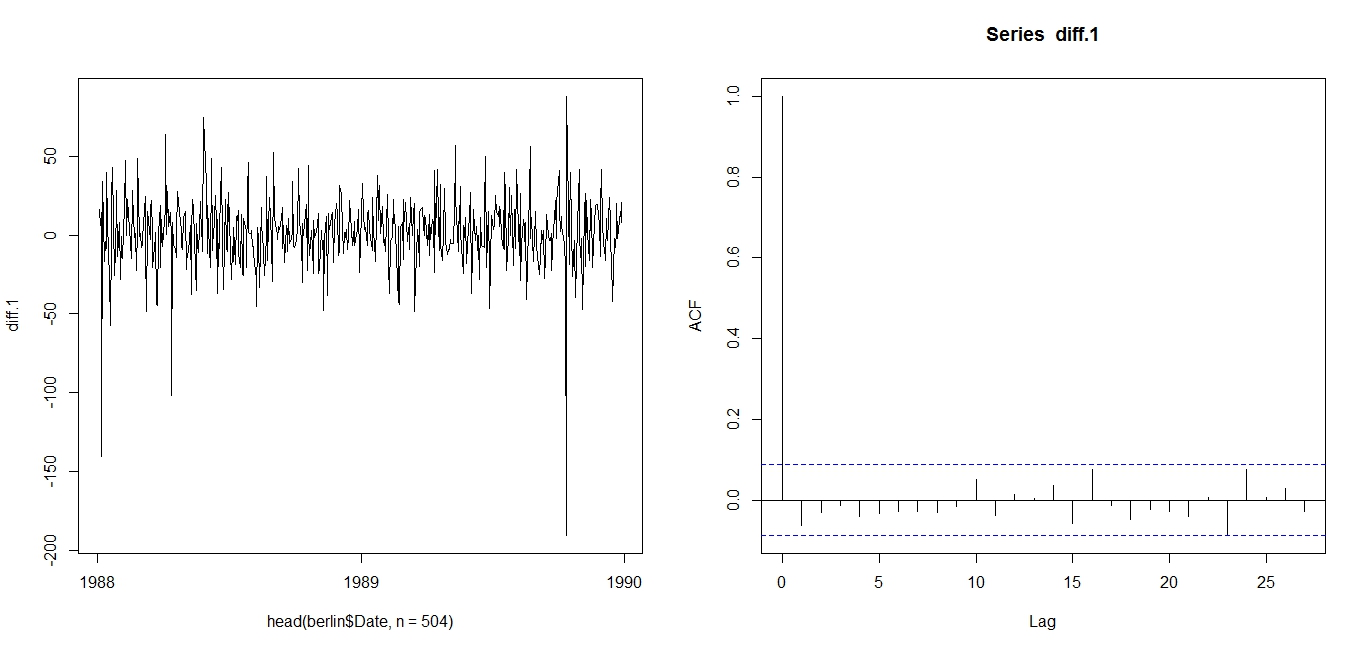
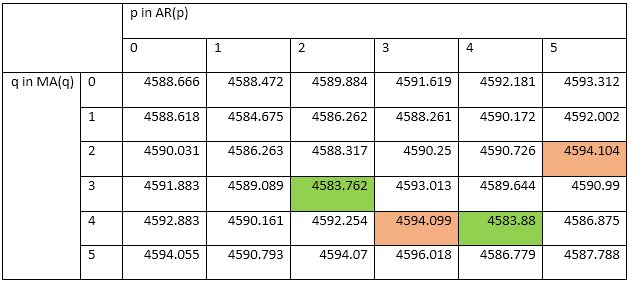
The AIC works as such: Some models, such as ARIMA(3,1,3), may offer better fit than ARIMA(2,1,3), but that fit is not worth the loss in parsimony imposed by the addition of additional AR and MA lags. Similarly, models such as ARIMA(1,1,1) may be more parsimonious, but they do not explain DJIA 1988-1989 well enough to justify such an austere model.
Note that the AIC has limitations and should be used heuristically. The above is merely an illustration of how the AIC is used. Nonetheless, it suggests that between 1988 and 1989, the DJIA followed the below ARIMA(2,1,3) model:
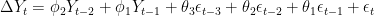
Next: Determining the above coefficients, and forecasting the DJIA.
Analysis conducted on R. Credits to the St Louis Fed for the DJIA data.
Abbas Keshvani

