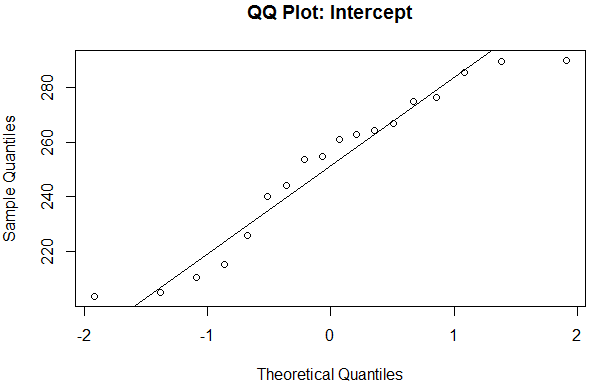
You produce a non-parametric distribution. Then you obtain, say, 10 random variables (RV) from this non-parametric distribution- much the same way as you would obtain random variables from a (parametric) normal distribution with stated mean and variance. But unlike the parametric distribution, where our RVs would occur around the mean (our parameter), RVs from a non-parametric distribution occur within the range bound by the lowest and highest mass point. This was not necessarily an intuitive concept to me, when I first stumbled across it. Which is why this mathematical proof of this range made me feel so much more comfortable:
If our estimate of the RV is a simple weighted-mean of the mass points:

Furthermore, since 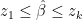

![\left[w_{1}+...+w_{k} \right]z_{1}\leq \hat{\beta}\leq \left[w_{1}+...+w_{k} \right]z_{k}](https://s0.wp.com/latex.php?latex=%5Cleft%5Bw_%7B1%7D%2B...%2Bw_%7Bk%7D+%5Cright%5Dz_%7B1%7D%5Cleq+%5Chat%7B%5Cbeta%7D%5Cleq+%5Cleft%5Bw_%7B1%7D%2B...%2Bw_%7Bk%7D+%5Cright%5Dz_%7Bk%7D&bg=ffffff&fg=000000&s=0&c=20201002)
Since 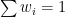
On the other hand, If we know further information, like individual weights:
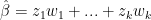
Furthermore, since for intercept 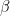

Since

Thus, it is proven that any estimates of an RV drawn from a non-parametric distribution will be bound by the highest and lowest mass point.
Abbas Keshvani